1. オートスケール機能の概要
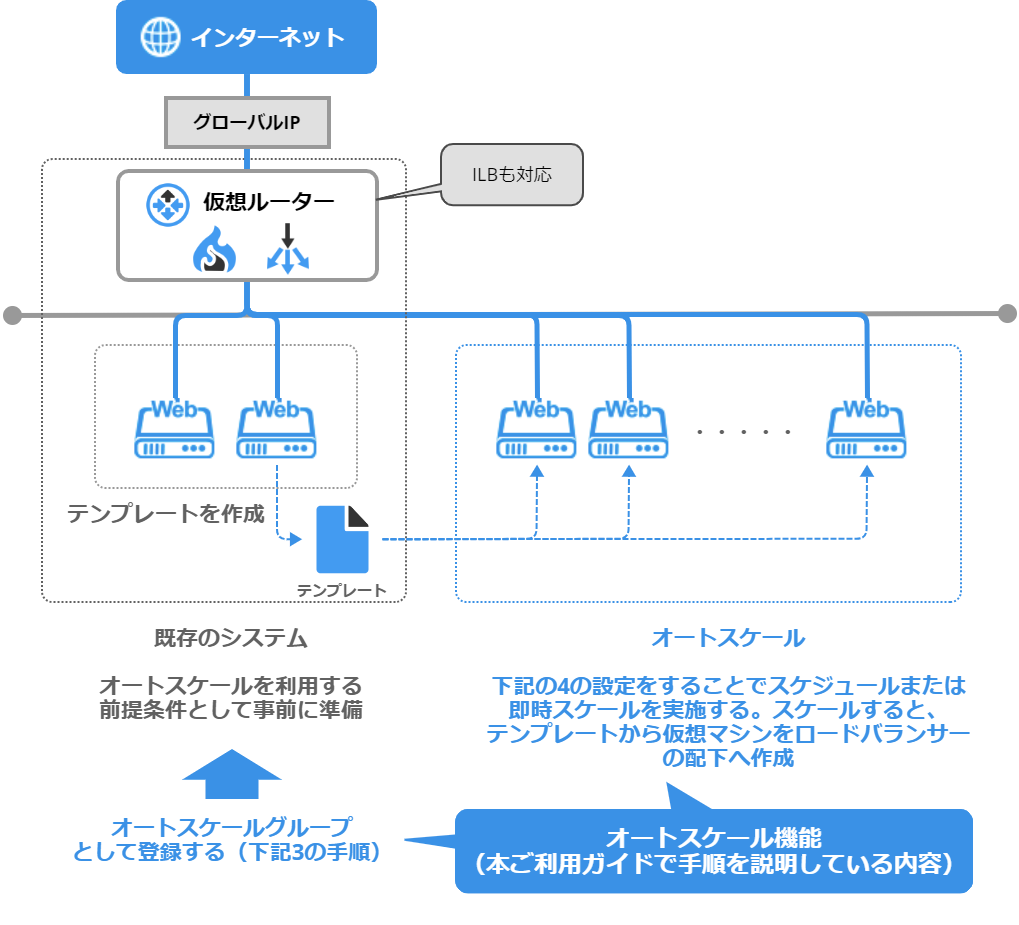
2. オートスケールを利用する前提条件
利用パターンと必要な項目
[仮想マシンの設定 - テンプレートから仮想マシンを作成/削除してスケールする場合]
1. 仮想マシンを作成し、スケールするテンプレートイメージを作成します。
テンプレート作成方法は、「スケーラブルなWebサイトを構築したい(Web2台構成編)」の「2. スナップショットの作成」と「3. テンプレートの作成」をご参照ください。
2. テンプレートID、ネットワークID、SSHキー名(任意)をクラウドコンソールから取得してメモしておきます。
3. idcfcloud-cliにてサービスオファリングIDを取得してメモしておきます。
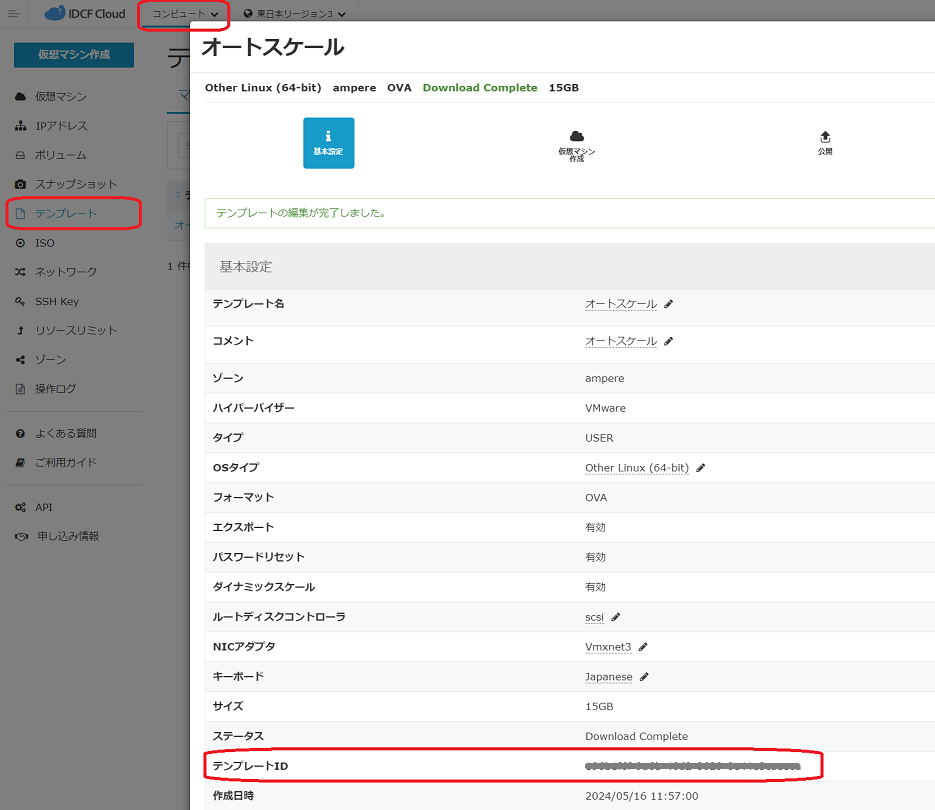
テンプレートID(template_id) の確認方法です。
画面遷移: コンピュート→テンプレート→テンプレートID
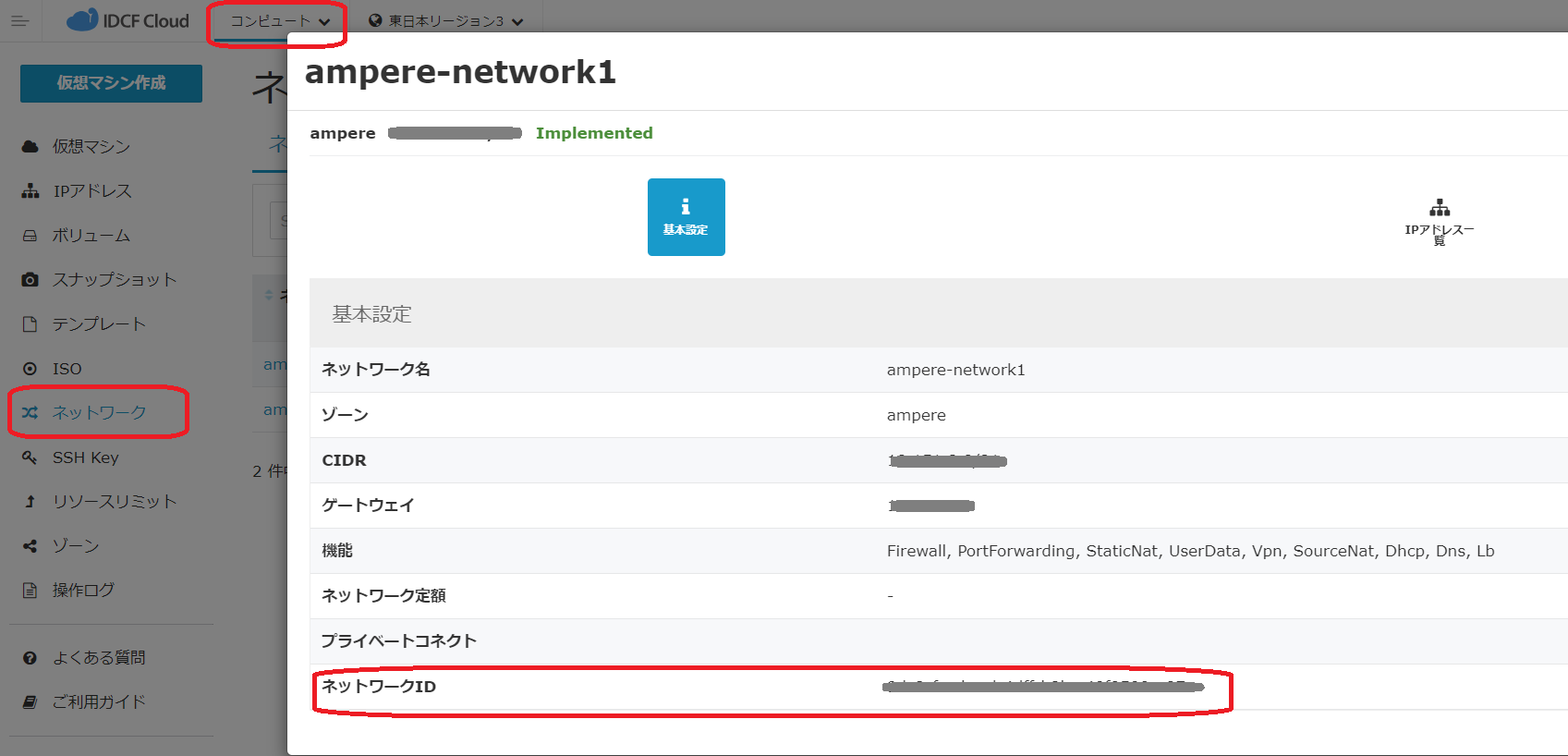
ネットワークID(network_ids) の確認方法です。
ネットワークID(UUID形式、複数指定可)
画面遷移: コンピュート→ネットワーク→ネットワーク名→ネットワークID
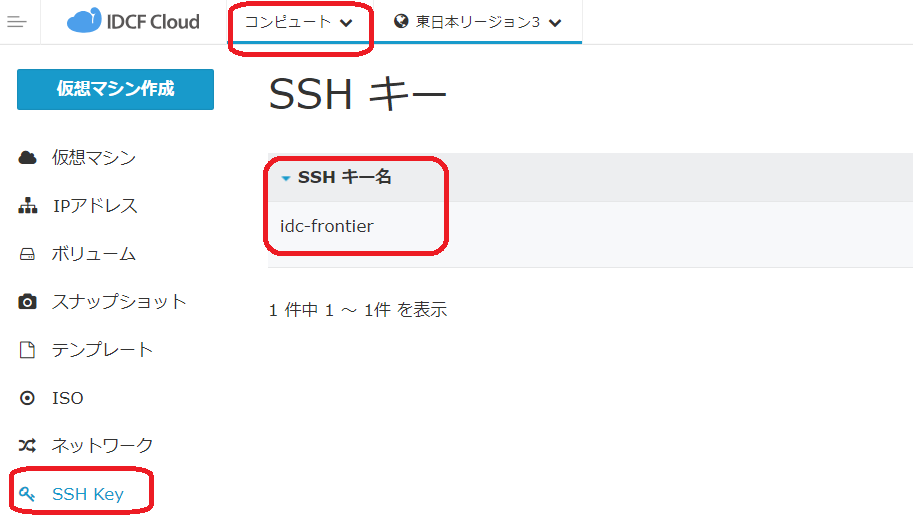
SSHキー名(key_pair) の確認方法です。
画面遷移: コンピュート→SSH Key→SSH キー名
### サービスオファリングID の取得方法
### サービスオファリング(サーバータイプ)ID。idcfcloud compute listServiceOfferings のid。
# idcfcloud compute listServiceOfferings
{
"status": 200,
"message": "",
"data": {
"count": 35,
"serviceoffering": [
{
"id": "5086385c-4f10-4b6f-9a8d-626c79ebe843", <-- 利用可能なマシンタイプからIDを選択
"name": "light.S1",
"displaytext": "1 CPU x 0.8 GHz / 1 GB RAM",
..
},
{
"id": "ae146354-497b-4671-a103-0d650f983370", <-- 利用可能なマシンタイプからIDを選択
"name": "light.S2",
"displaytext": "1 CPU x 1.6 GHz / 2 GB RAM",
..
},
..
]
}
}
[仮想マシンの設定 - 作成した仮想マシンを起動/停止してスケールする場合]
1. 仮想マシンをスケールする台数分作成し、停止しておきます。
2. 仮想マシンIDをクラウドコンソールから取得してメモしておきます。
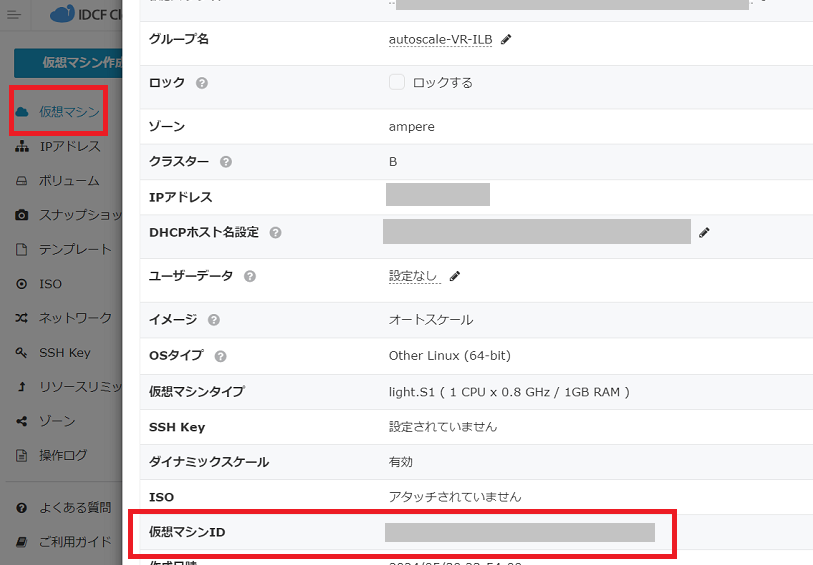
仮想マシンID の確認方法です。
画面遷移: コンピュート→仮想マシン→仮想マシン名→仮想マシンID
[ロードバランサーの設定 - スケール時に仮想ルーターのロードバランサーに仮想マシンを割当/解除する場合]
1. IPアドレスを作成します。
2. ロードバランサールールを作成し、スケールするマシンを割り当てます。
※0台にする時間帯が発生する場合は、idcfcloud-cliにてロードバランサールールから仮想マシンを解除しておきます。
idcfcloud compute removeFromLoadBalancerRule '{"id": "<ロードバランサールールID>", "virtualmachineids": "<ロードバランサールールに一時的に割り当てた仮想マシンID>"}'
3. idcfcloud-cliにてロードバランサールールを取得し、ロードバランサールールIDをメモしておきます。
### ロードバランサールールID の取得方法
### ロードバランサールールID(UUID形式、複数指定可)。#idcfcloud compute listLoadBalancerRules のid。
# idcfcloud compute listLoadBalancerRules
{
"status": 200,
"message": "",
"data": {
"count": 1,
"loadbalancerrule": [
{
"id": "01234567-89ab-cdef-0123-456789abcdef", <-- ロードバランサーのリストからidを取得。
"name": "autoscale",
..
}
]
}
}
[ロードバランサーの設定 - スケール時にインフィニットLBに仮想マシンを割当/解除する場合]
1. ILBを作成して、設定します。(最低1台は割り当てる必要があり、スケールアウト時に0台にすることはできません)
ILBの作成方法は「インフィニットLB」を活用したWebサーバーの負荷分散 の 「1. インフィニットLBの作成」をご参照ください。
2. フロントエンドプロトコル、フロントエンドポート番号、バックエンドプロトコル、バックエンドポート番号をクラウドコンソールから取得してメモしておきます。
3. idcfcloud-cliにてロードバランサーを取得し、ロードバランサーIDをメモしておきます。
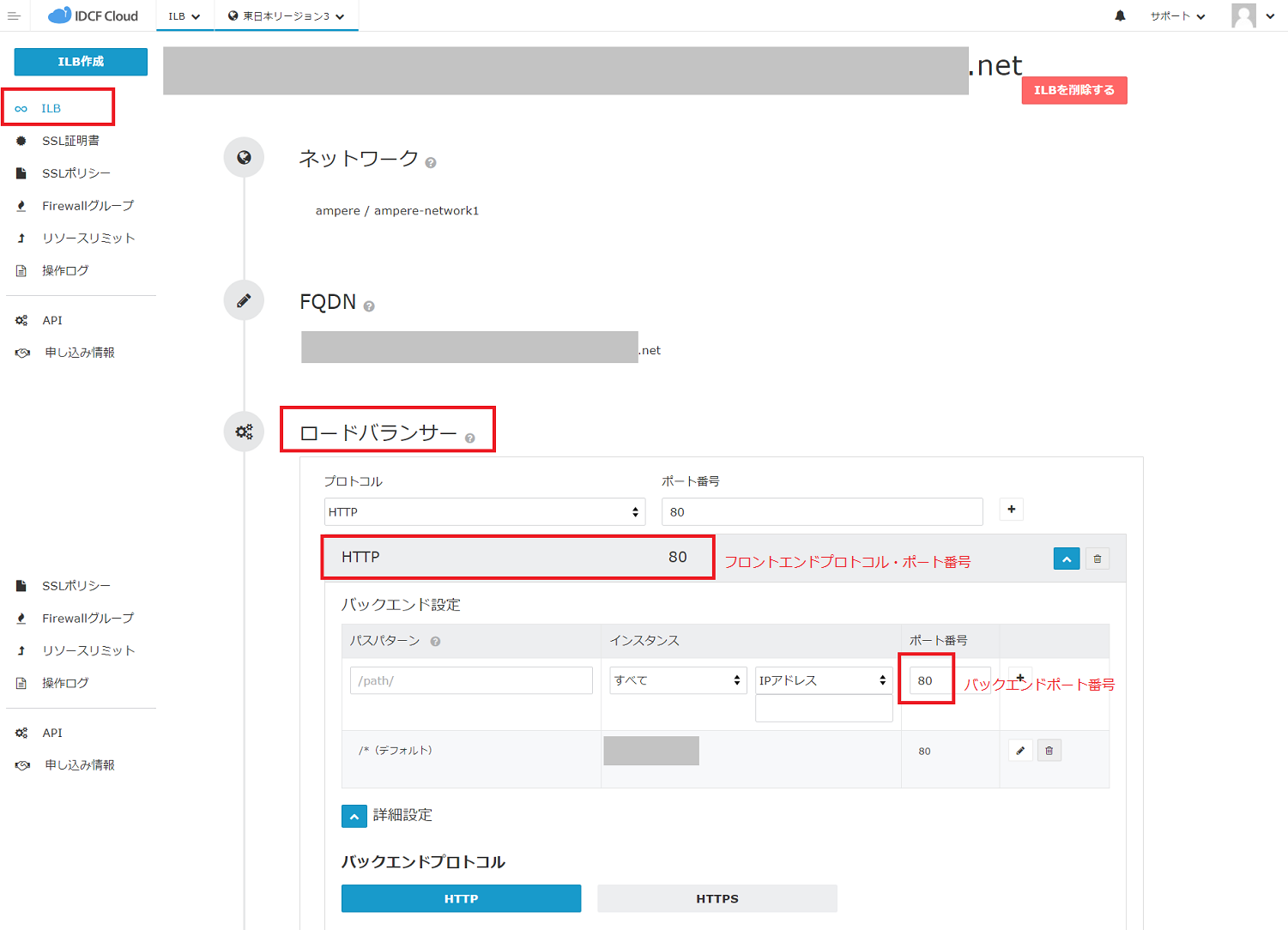
フロントエンドプロトコル、フロントエンドポート番号、バックエンドプロトコル、バックエンドポート番号
の確認方法です。
### ロードバランサーID の確認方法
### ロードバランサーID(UUID形式)。#idcfcloud ilb list_loadbalancers のid。
# idcfcloud ilb list_loadbalancers
{
"status": 200,
"message": "",
"data": [
{
"id": "01234567-89ab-cdef-0123-456789abcdef", <--- ロードバランサーID(UUID形式)id。
"account_id": "00000000000",
...
}
]
}
以下API共通の必要な項目になります。
### ゾーンID の確認方法です。
### ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
# idcfcloud compute listZones
{
"status": 200,
"message": "",
"data": {
"count": 2,
"zone": [
{
"id": "01234567-89ab-cdef-0123-456789abcdef", <-- ゾーンのリストからIDを取得。
"name": "volt",
..
},
{
"id": "01234567-89ab-cdef-0123-456789ghijkl", <-- ゾーンのリストからIDを取得。
"name": "ampere",
..
}
]
}
}
リージョン名の確認方法です。
region_name(jp-east/jp-east-2/jp-east-3/jp-west)
この場合、東日本リージョン3 = jp-east-3 となります。
API操作の準備
オートスケールの利用はAPIのみ提供となっております。
「API Docs」はこちらを参照ください。
APIを利用するためのエンドポイントや、API Key、Secret Keyの取得は以下の手順で取得できます。
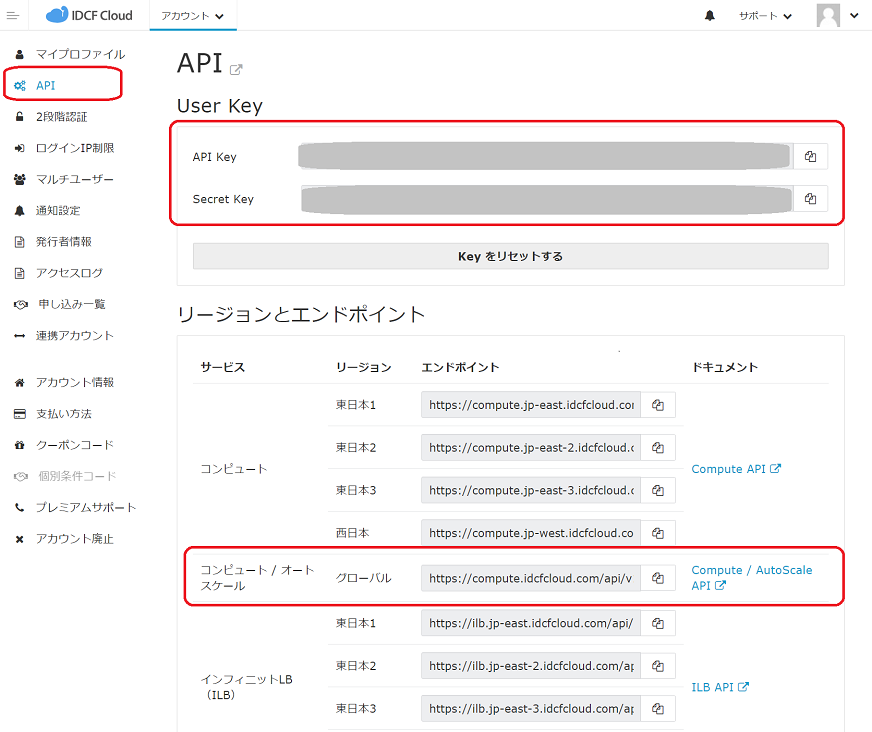
プルダウンメニューから[アカウント設定]をクリックします。
左メニューから[API]をクリックし、API画面を表示します。
API Key、Secret Keyおよびコンピュート / オートスケールのエンドポイントを確認して以降の手順で使用できるようにしておきます。
簡単にAPIを利用して操作を行うために、「idcfcloud-cli」が便利です。
「idcfcloud-cli」のインストールおよび初期設定方法については「API Docs」 をご参照ください。
表示例は以下のとおりです。
# idcfcloud Commands: idcfcloud autoscale [OPTION] # Autoscale Service idcfcloud compute [OPTION] # Computeing Service idcfcloud configure # create configure idcfcloud dns [OPTION] # DNS Service idcfcloud help [COMMAND] # Describe available commands or one specific... idcfcloud ilb [OPTION] # ILB Service idcfcloud init # initialize idcfcloud update # list update idcfcloud version # version string idcfcloud your [OPTION] # Your Service
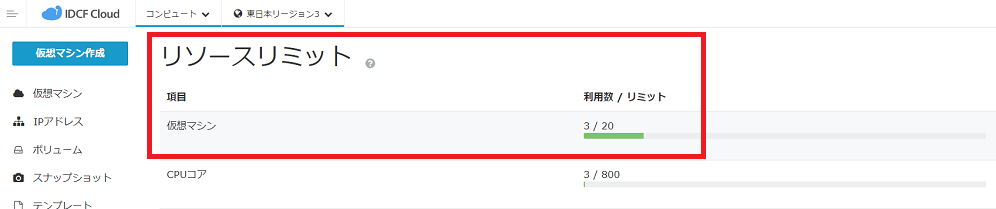
事前に仮想マシンのリソースリミットに余裕があるかをご確認ください。
※ コンピュートのリソースリミットの引き上げは事前に実施する必要があります。
以上でオートスケールを利用する前提条件の設定は完了です。
3. グループ登録
スケールするグループを登録します。
APIの概要は以下のとおりです。
| やりたいこと | API | APIリファレンス | 設定内容 |
|---|---|---|---|
新しく仮想マシンを作成・削除したい |
POST api/v1/autoscale/groups |
createGroup_CreateDeleteVM_VRLB |
スケール時に仮想マシンを作成/削除し、仮想ルーターのロードバランサーに割当/解除するグループを作成する |
| createGroup_CreateDeleteVM_ILB | スケール時に仮想マシンを作成/削除し、インフィニットLB (ILB)に割当/解除するグループを作成する | ||
| createGroup_CreateDeleteVM | スケール時に仮想マシンを作成/削除するグループを作成する | ||
既存の仮想マシンを起動・停止したい |
createGroup_StartStopVM_VRLB | スケール時に指定した仮想マシンを起動/停止し、仮想ルーターのロードバランサーに割当/解除するグループを作成する | |
| createGroup_StartStopVM_ILB | スケール時に指定した仮想マシンを起動/停止し、インフィニットLB (ILB)に割当/解除するグループを作成する | ||
| createGroup_StartStopVM | スケール時に指定した仮想マシンを起動/停止するグループを作成する | ||
| グループの一覧を取得したい | GET api/v1/autoscale/groups | listGroups | すべてのグループを表示する (削除済のグループは表示されない) |
| グループを削除したい | DELETE api/v1/autoscale/groups/:group_uuid | deleteGroup | グループを削除する (有効なスケジュールが登録されている場合は削除不可) |
APIリクエストの設定内容を解説します。
新しく仮想マシンを作成・削除したい (createGroup_CreateDeleteVM_VRLB )
# idcfcloud autoscale createGroup_CreateDeleteVM_VRLB
'{
"name": "autoscale-VRLB", -- グループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "create-delete", -- 作成削除
"parameters": {
"service_offering_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。 サービスオファリング(サーバータイプ)ID。#idcfcloud compute listServiceOfferings のid。
"template_id": "01234567-89ab-cdef-0123-456789abcdef", -- クラウドコンソールで確認。 コンピュート→テンプレート→テンプレートID。
"key_pair": "idc-frontier", -- クラウドコンソールで確認。 SSHキー名。コンピュート→SSH Key→SSH キー名。
"network_ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 ネットワークID(UUID形式、複数指定可) 。 コンピュート→ネットワーク→ネットワーク名→ネットワークID。
]
}
},
"load_balancer": {
"type": "virtual-router",
"parameters": {
"rule_ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- コマンドで確認。ロードバランサールールID(UUID形式、複数指定可)。# idcfcloud compute listLoadBalancerRules のid。
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
新しく仮想マシンを作成・削除したい (createGroup_CreateDeleteVM_ILB)
# idcfcloud autoscale createGroup_CreateDeleteVM_ILB
'{
"name": "autoscale-VR-ILB", -- 任意のグループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "create-delete",
"parameters": {
"service_offering_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。 サービスオファリング(サーバータイプ)ID。#idcfcloud compute listServiceOfferings のid。
"template_id": "01234567-89ab-cdef-0123-456789abcdef", -- クラウドコンソールで確認。 コンピュート→テンプレート→テンプレートID。
"key_pair": "idc-frontier", -- クラウドコンソールで確認。 SSHキー名。コンピュート→SSH Key→SSH キー名。
"network_ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 ネットワークID(UUID形式、複数指定可) 。 コンピュート→ネットワーク→ネットワーク名→ネットワークID。
]
}
},
"load_balancer": {
"type": "ilb",
"parameters": {
"id": "0b2f8bae-0fd0-40d0-b10d-c55ef2f110f2", -- コマンドで確認。# idcfcloud ilb list_loadbalancers のid。
"configs": [
{
"frontend_protocol": "http", -- クラウドコンソールで確認。 ILB→ロードバランサー→プロトコル
"frontend_port": 80, -- クラウドコンソールで確認。 ILB→ロードバランサー→ポート番号
"backend_protocol": "http", -- クラウドコンソールで確認。 ILB→ロードバランサー→バックエンド設定
"backend_port": 80 -- クラウドコンソールで確認。 ILB→ロードバランサー→バックエンド設定のポート番号
}
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
新しく仮想マシンを作成・削除したい (createGroup_CreateDeleteVM)
# idcfcloud autoscale createGroup_CreateDeleteVM
'{
"name": "autoscale-VM", -- 任意のグループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "create-delete",
"parameters": {
"service_offering_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。 サービスオファリング(サーバータイプ)ID。#idcfcloud compute listServiceOfferings のid。
"template_id": "01234567-89ab-cdef-0123-456789abcdef", -- クラウドコンソールで確認。 コンピュート→テンプレート→テンプレートID。
"key_pair": "idc-frontier", -- クラウドコンソールで確認。 SSHキー名。コンピュート→SSH Key→SSH キー名。
"network_ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 ネットワークID(UUID形式、複数指定可) 。 コンピュート→ネットワーク→ネットワーク名→ネットワークID。
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
既存のVMを起動・停止したい (createGroup_StartStopVM_VRLB)
# idcfcloud autoscale createGroup_StartStopVM_VRLB
'{
"name": "autoscale-SS-VRLB", -- 任意のグループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "start-stop",
"parameters": {
"ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 仮想マシンID。コンピュート→仮想マシン→仮想マシンID。
]
}
},
"load_balancer": {
"type": "virtual-router",
"parameters": {
"rule_ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- コマンドで確認。ロードバランサールールID(UUID形式、複数指定可)。# idcfcloud compute listLoadBalancerRules のid。
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
既存のVMを起動・停止したい (createGroup_StartStopVM_ILB)
# idcfcloud autoscale createGroup_StartStopVM_ILB
'{
"name": "autoscale-SS-ILB", -- 任意のグループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "start-stop",
"parameters": {
"ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 仮想マシンID。コンピュート→仮想マシン→仮想マシンID。
]
}
},
"load_balancer": {
"type": "ilb",
"parameters": {
"id": "0b2f8bae-0fd0-40d0-b10d-c55ef2f110f2", -- コマンドで確認。# idcfcloud ilb list_loadbalancers のid。
"configs": [
{
"frontend_protocol": "http", -- クラウドコンソールで確認。 ILB→ロードバランサー→プロトコル
"frontend_port": 80, -- クラウドコンソールで確認。 ILB→ロードバランサー→ポート番号
"backend_protocol": "http", -- クラウドコンソールで確認。 ILB→ロードバランサー→バックエンド設定
"backend_port": 80 -- クラウドコンソールで確認。 ILB→ロードバランサー→バックエンド設定のポート番号
}
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
既存のVMを起動・停止したい (createGroup_StartStopVM)
# idcfcloud autoscale createGroup_StartStopVM
'{
"name": "autoscale-SS-VM", -- 任意のグループ名(半角の英大小文字、数字、チルダ(~)以外の記号、スペースを使用可能)
"virtual_machine": {
"type": "start-stop",
"parameters": {
"ids": [
"01234567-89ab-cdef-0123-456789abcdef" -- クラウドコンソールで確認。 仮想マシンID。コンピュート→仮想マシン→仮想マシンID。
]
}
},
"zone_id": "01234567-89ab-cdef-0123-456789abcdef", -- コマンドで確認。ゾーンID(UUID形式)。# idcfcloud compute listZones のid。
"region_name": "jp-east-3" -- クラウドコンソールで確認。 リージョン名。(jp-east/jp-east-2/jp-east-3/jp-west)
}'
グループの一覧を取得したい (listGroups)
# idcfcloud autoscale listGroups
グループを削除したい (deleteGroup)
### group_uuidを指定する # idcfcloud autoscale deleteGroup 0000000-90a7-0000-abcd-abcdef000000
グループAPIの注意事項
[グループ登録の注意事項]
・以下の2つのパターンを組み合わせて登録することはできません。
①テンプレートを指定して、スケール時に仮想マシンを作成/削除する。
②仮想マシンを指定して、スケール時に仮想マシンを起動/停止する。
・他のグループで利用したロードバランサー/ルール、仮想マシンを新たなグループに登録することはできません。
[グループ削除の注意事項]
・有効なオートスケールスケジュールが存在する場合は、グループ削除はできません。(先にオートスケールスケジュール削除を行う必要があります)
・オートスケールにて作成/起動/ロードバランサーへ割当した仮想マシンは、削除/停止/ロードバランサーからの解除は行いません。
4. スケジュール登録、実際にスケール
スケールするスケジュールを登録します。
APIの概要は以下のとおりです。
| やりたいこと | API | APIリファレンス | 設定内容 |
| 指定された日時にスケールを実行するスケジュールを作成したい | POST api/v1/autoscale/groups/:group_uuid/schedules |
createSchedule_Once | 指定された日時にスケールを実行するスケジュールを作成する |
| Unix-cron式で指定し、定期的にスケールを実行するスケジュールを作成したい | createSchedule_Cron | Unix-cron式で指定し、定期的にスケールを実行するスケジュールを作成する | |
| 手動スケールを実行したい | POST api/v1/autoscale/groups/:group_uuid/manual_run | manualRun | 即座にスケールを実行する |
| スケジュールの一覧を表示したい | GET api/v1/autoscale/schedules{?state} | listSchedules | すべてのスケジュールを表示する ・「type: quick」は手動スケール実行(manualRun)を表す) ・実行予定のスケジュールを表示する場合は指定しない ・スケジュールの状態(完了済みのスケジュールを表示する場合は「completed」を指定 |
| スケジュールを削除したい | DELETE api/v1/autoscale/schedules/:schedule_uuid | deleteSchedule | スケジュールを削除する |
指定された日時にスケールを実行するスケジュールを作成する (createSchedule_Once)
### group_uuid を指定する
# idcfcloud autoscale createSchedule_Once 0000000-90a7-0000-abcd-abcdef000000
'{
"desired_capacity": 5, -- 希望する仮想マシンの台数(オートスケール管理外の仮想マシンを除く全体台数(増分/減分の台数でない)を指定)
"type": "once", -- 指定した日時にスケールを実行する場合は「once」を指定
"value": "2025-01-31 13:00" -- スケール実行日時(YYYY-MM-DD HH:MM形式、15分後から1年後の0:00までを指定可、日本標準時)
}'
Unix-cron式で指定し、定期的にスケールを実行するスケジュールを作成したい (createSchedule_Cron)
### group_uuid を指定する
# idcfcloud autoscale createSchedule_Cron 0000000-90a7-0000-abcd-abcdef000000
'{
"desired_capacity": 5, -- 希望する仮想マシンの台数(オートスケール管理外の仮想マシンを除く全体台数(増分/減分の台数でない)を指定)
"type": "cron", -- Unix-cron式を指定し、定期的にスケールを実行する場合は「cron」を指定
"value": "00 07 * * *" -- スケール実行タイミング(Unix-cron式、日本標準時)
}'
手動スケールを実行したい (manualRun)
### group_uuid を指定する
# idcfcloud autoscale manualRun 0000000-90a7-0000-abcd-abcdef000000
'{
"desired_capacity": 1 -- 希望する仮想マシンの台数(オートスケール管理外の仮想マシンを除く全体台数(増分/減分の台数でない)を指定)
}'
スケジュールの一覧を表示したい (listSchedules)
# idcfcloud autoscale listSchedules
スケジュールを削除したい (deleteSchedule)
### schedule_uuidを指定する # idcfcloud autoscale deleteSchedule 0000000-90a7-0000-abcd-abcdef000000
実際にスケールされると、クラウドコンソールでは以下のように確認できます。
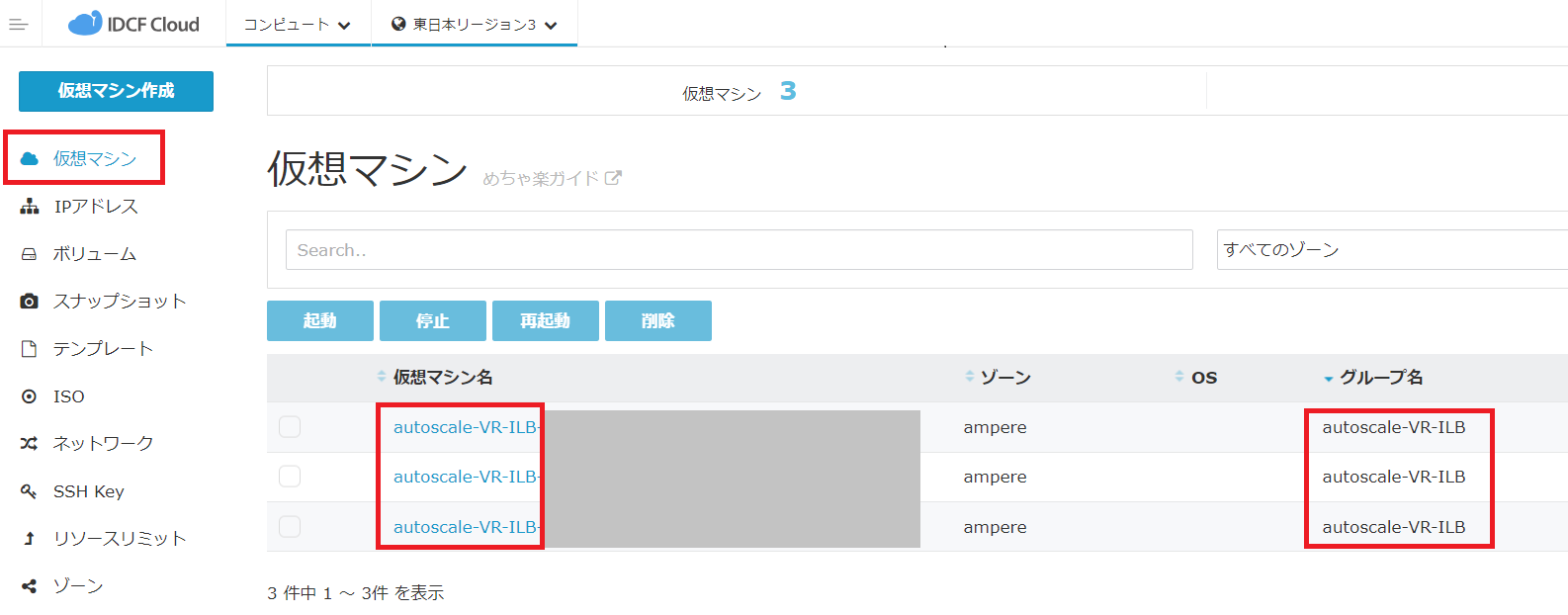
グループ名が仮想マシン名の先頭 & 仮想マシンのグループ名に登録されます。
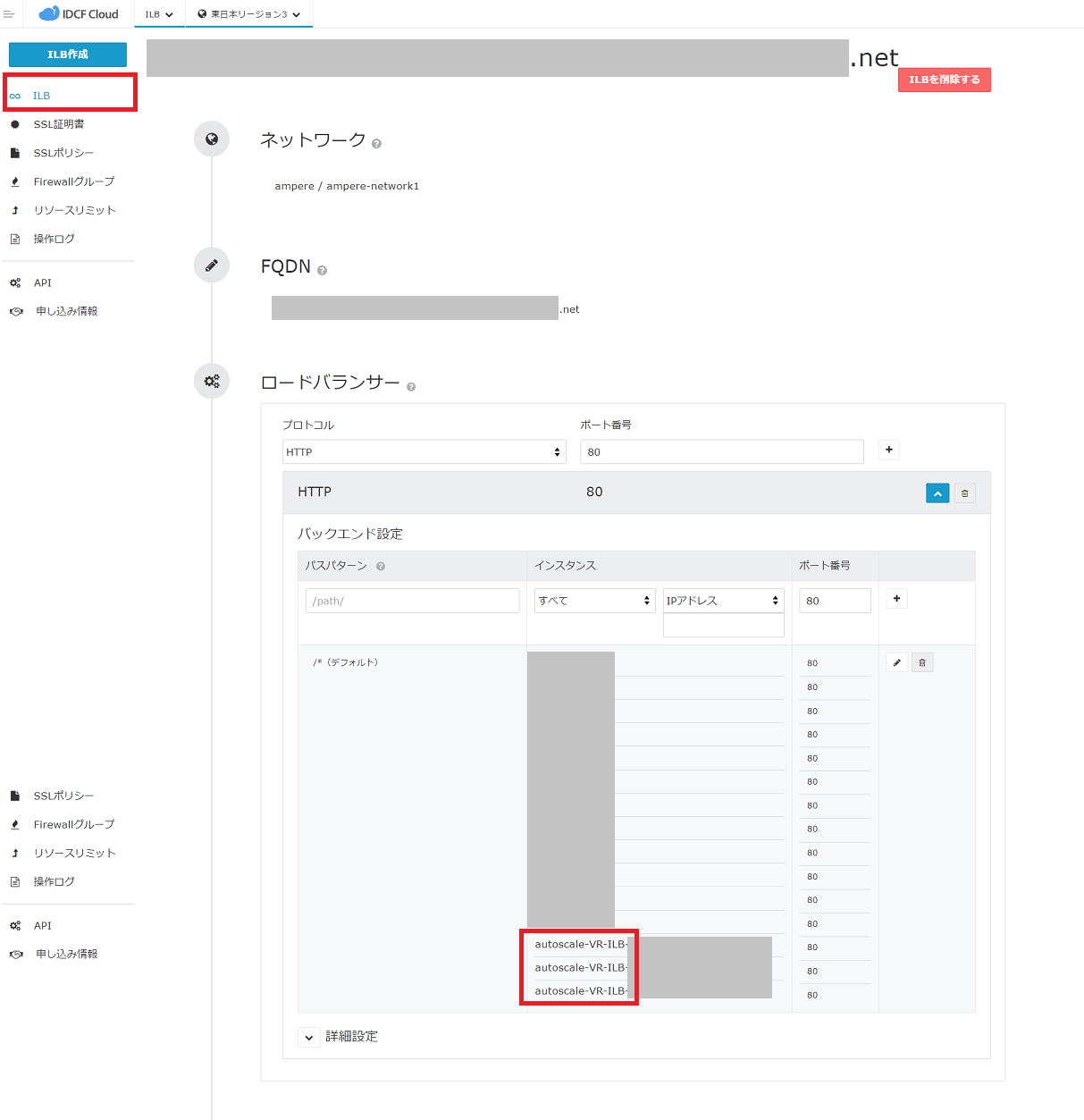
ILBを設定の場合。
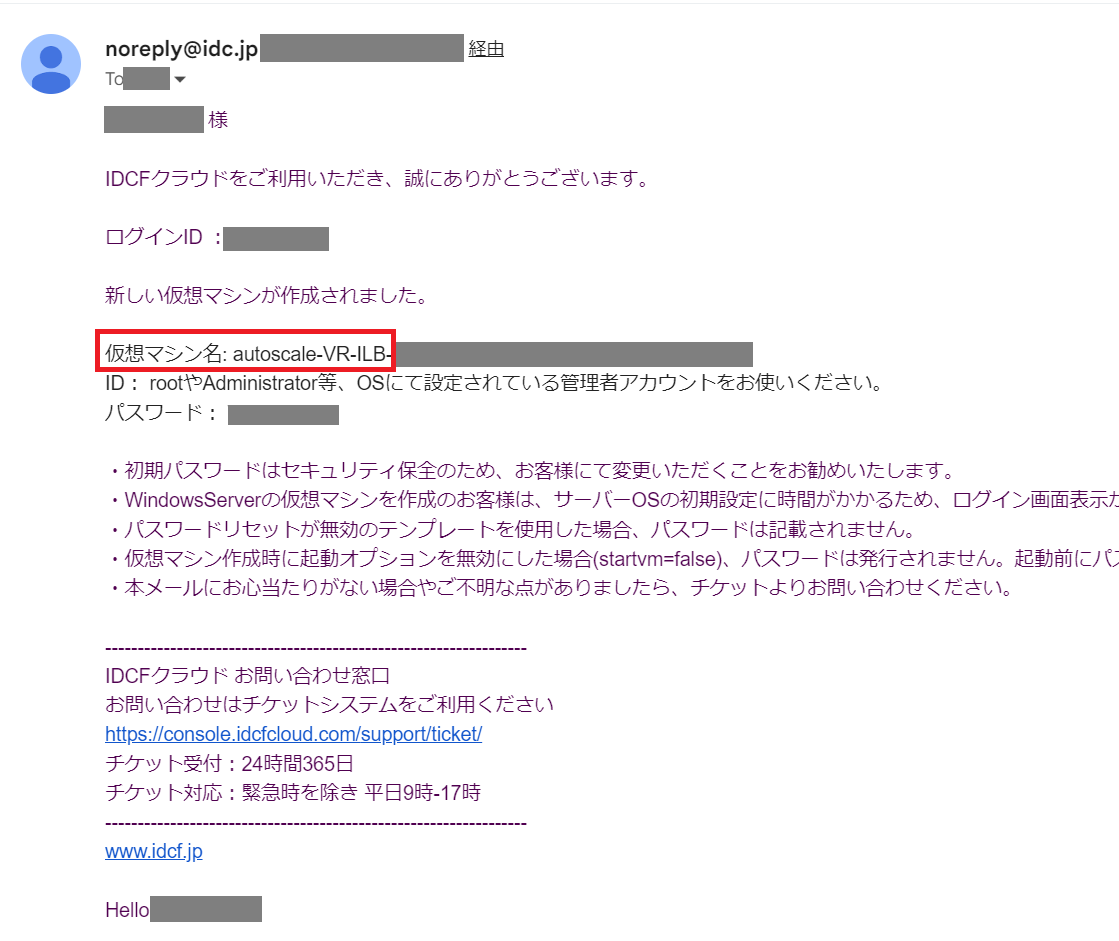
アカウント設定 > 通知設定 > メール受信設定にて「仮想マシンの作成完了通知を受信する」が有効な場合、「新しい仮想マシンが作成されました」のメールが届きます。
スケジュールAPIの注意事項
[希望する仮想マシンの台数 (desired_capacity)について]
・希望する仮想マシンの台数 (desired_capacity) は、オートスケールにて管理されている仮想マシンのみが対象です。
virtual_machine.type = create-delete (テンプレートから仮想マシンを作成/削除してスケールする) 場合
→事前にロードバランサーに割り当てている1台目の仮想マシンは台数にカウントしません。
virtual_machine.type = start-stop (仮想マシンを起動/停止してスケールする) 場合
→ロードバランサーに割り当てている1台目の仮想マシンは virtual_machine.parameters.ids に指定していない場合、台 数にカウントしません。
また、インフィニットLBを利用する場合、必ず1台は割り当てられた状態にすることが必要なため、0台へのスケールアウトはできません。
[スケジュールの日時、制約事項について]
・特定の日時にスケジュールを設定する場合、現在時刻の15分後から1年後の0:00までを設定可能です。
例: 今12:00→12:15以降に設定可能
・Unix-cron式 (分/時/日/月/曜の半角スペース区切り) によって繰り返しのスケジュールを設定する場合、以下の制約があります。
「時」および「分」は「半角数字」が指定可能です。
「日」「月」「曜」は「半角数字」「*」「-」「,」が指定可能です。
・スケジュールにおけるタイムゾーンは日本時間(Asia/Tokyo)となります。
・スケジュールに設定された日時は、スケールが完了する日時ではなく、スケールを開始する日時となります。
スケール完了日時の保証はできないため、余裕をもった日時をご設定ください。
・同一グループに対するスケジュール設定の前後15分は新たにスケジュールを登録することはできません。
・スケール中に新たなスケジュールが動作した場合、スケールに失敗することがあります。
・同一グループに対する1回のスケジュールでの増減台数は10台までです。 10台を超える場合はスケールを行わずスケール失敗となります。
10台を超えるスケールを行いたい場合は、以下のような設定をご検討ください。
例: 毎日14:00に20台にしたい場合
type: cron, value: 20 13 * * *, desired_capacity: 10 を設定
type: cron, value: 40 13 * * *, desired_capacity: 20 を設定
※15-20分でスケールできるテンプレートを指定した場合。テンプレートによりスケール時間は変動するため、余裕をもったスケジュールをご設定ください。
5. スケールに失敗した場合
スケールに失敗した場合、設定されたアカウントのマスターユーザー・パワーユーザー・ユーザーに対してメールにて通知されます。
現在、失敗通知を一部のユーザーに限定することや、失敗通知を受け取らないように設定することはできません。
5回まで再試行、毎回通知します。
5回以上は再実行・通知されません。 失敗が続いている場合は、仮想マシンやロードバランサーの状況をご確認ください。
スケール失敗時にロードバランサーへの設定に失敗した場合は仮想マシンが残る場合があります。その場合は、ご自身で削除をお願いいたします。
[スケールが失敗する例]
・コンピュートのリソースリミットの上限値を超えてスケール設定を行っていた場合
・コンピュートやインフィニットLBのメンテナンス期間中にスケールが行われた場合
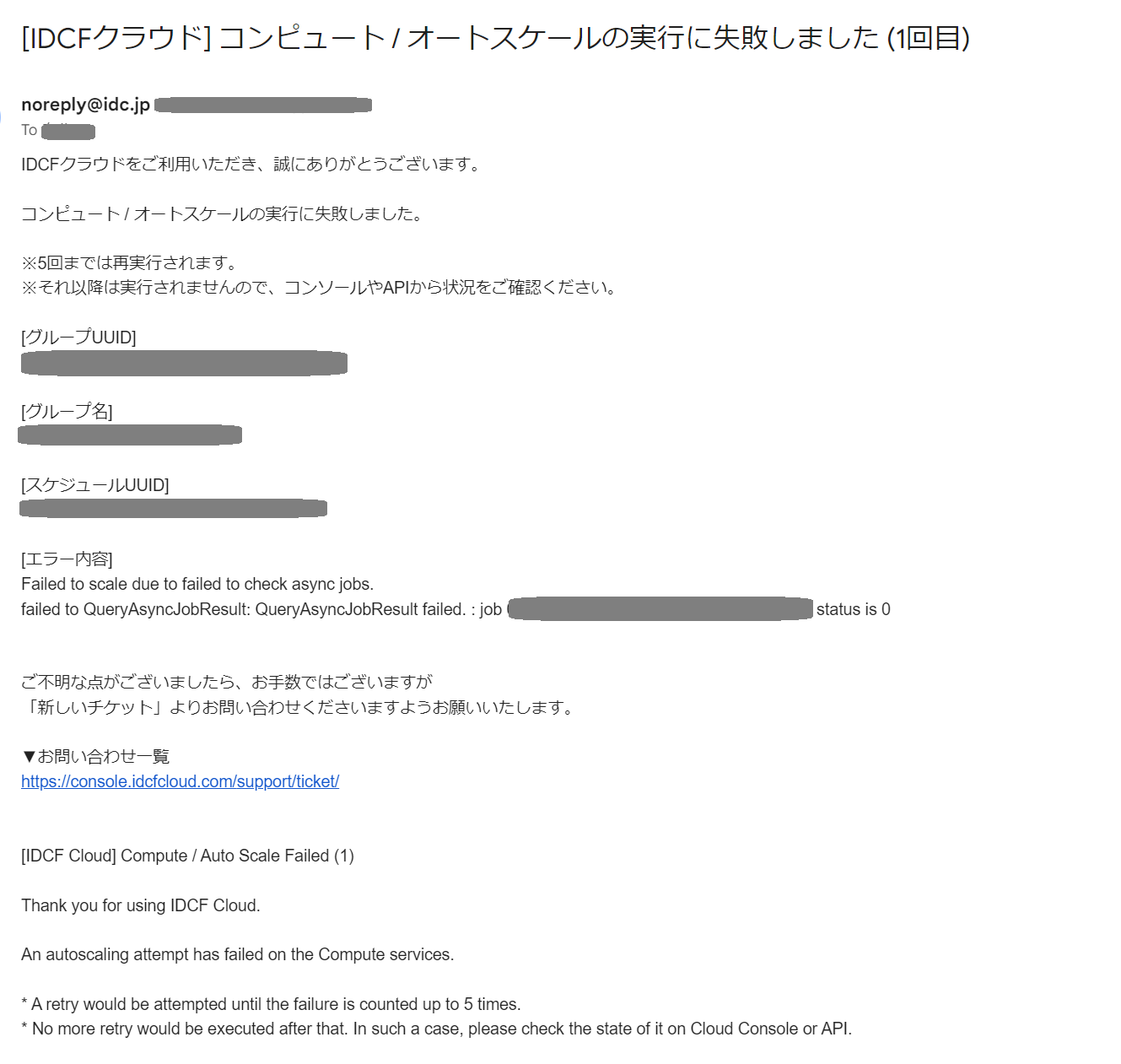
スケールに失敗した場合、このようなメールが届きます。
お問い合わせにはメールの内容の記載をお願いいたします。
6. ご利用の注意点
※ 本機能は、設定した台数のスケールを保証するものではありません。
※ リソースリミットの引き上げは事前に実施する必要があります。
※ スケールスケジュールは、仮想マシンの作成/起動処理を開始する時間であり、完了時間ではありません。
※ オートスケールのメンテナンスによりAPIが利用不可となった場合、スケールに失敗する恐れがあります。メンテナンスのスケジュールは事前に通知されます。
※ IDCFクラウドのコンピュートやインフィニットLBのメンテナンスの影響でスケールに失敗するおそれがあります。
[アカウントについて]
※ 有効なアカウントである場合のみ、実行可能 です。(=削除または無効なアカウントの場合、失敗通知は送信しません。)
※ スケジュール実行時に、スケジュールを登録したユーザーが削除されている場合、または無効となっている場合も実行できません。
[ご要望・お問い合わせについて]
※ お問い合わせに関してはIDCFクラウドコンソール右上の「サポート→お問い合わせ」から新しいチケットを作成し、サービスに「コンピュート」を選択してお問い合わせをお願いいたします。
※ 現在提供しておりませんが、今後の追加対応を検討しておりますので、ご要望いただけますと幸いです。
・IDCFクラウドコンソール上のコンピュートのUIでの設定
・モニタリングしたリソースの値をもとにしたトリガー






