参加者レポート - GPUクラウドAI推進プログラム -
大規模言語モデルを活用したニュース・タイムラインの自動振り分け
時事通信社

- 中間レポート
- 最終レポート
2024年7月時点
開発/研究の目的
時事通信社は、国内外に張り巡らされた取材網から集まる政治、経済、社会、国際、スポーツなどのニュースや写真を新聞やテレビなどのメディア、専門機関に配信しています。 また、自社で運営するニュースサイト「時事ドットコム」を通じて、インターネット上で直接読者にニュースを届けています。
時事ドットコムでは、トピックごとにタイムライン形式のページを作成し、関連するニュースを分かりやすく表示するコーナーを設けています。
ページの更新は編集者が手作業で行っていますが、毎日新しいニュースが飛び込んでくる通信社の現場では、トピックが増え続けることで更新の遅れや漏れが生じる可能性があります。
そのため、AIの力を活用して記事がどのトピック(タイムラインページ)に該当するかを自動的に判断し、候補を推論するモデルを作成したいと考えています。
全体のプロセス
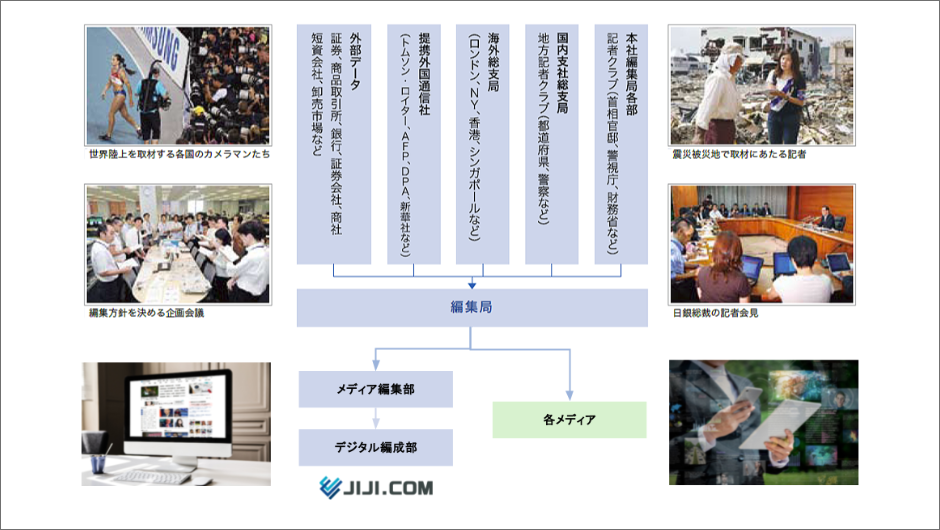
時事通信の出稿部(政治部、経済部、社会部など)、地方支局や海外拠点に所属する記者やカメラマンは、国内外の出来事を取材し、原稿や写真等の素材を本社に送ります。
本社編集局に集約されたこれらの素材は、デスクによるチェックや整理部によるダブルチェックを経て、各メディアへ配信されます。 インターネット向けのコンテンツは、記事や写真を専用のフォーマットに編集し、関連情報を付加した上で、時事ドットコムやポータルサイト等に配信されています。
デジタル編成部は自社ニュースサイトの運営を担当しているセクションで、「時事ドットコム」の画面編成を行っています。
同部の仕事の一つに配信されたニュースのピックアップと振り分け作業があります。
これは記事を特定のトピック(タイムラインページ)に分類し、掲載する作業です。
現在、豊富な取材経験を持つベテランのデスクが記事の取捨選択とトピックの選定を担当しています。
ベテランの作業内容を機械学習することで、現在の分類精度を保ちながら、より多くの記事に対して迅速に対応できる状態を目指します。

使用されているAI技術やアルゴリズム
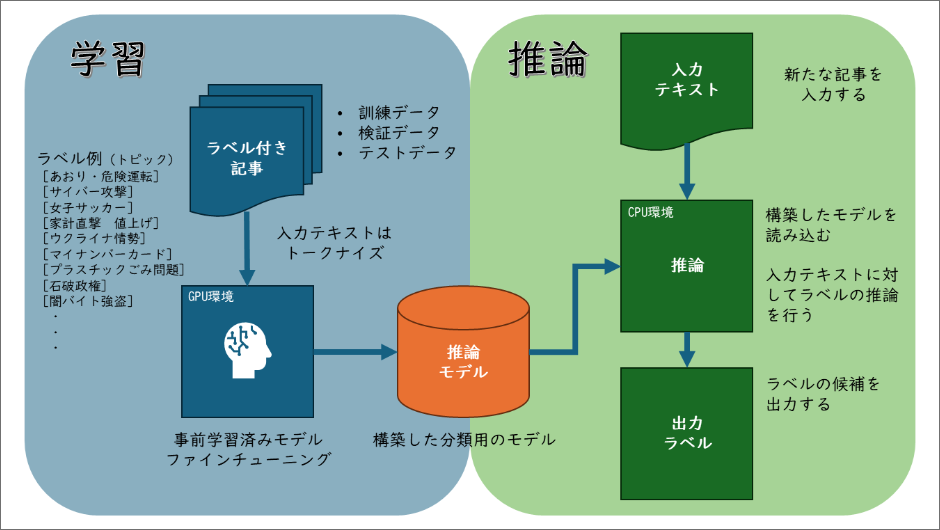
日本語の事前学習済み大規模言語モデル(LLM)に対して、これまでにデスク(編集者)が手動で分類したデータを用いてファインチューニングを行い、記事を分類するモデルを作成します。
近年、世界中で注目を集めている生成AIの基盤となる「大規模言語モデル」を、多くの企業や研究機関が開発しています。
大規模言語モデルは、大量のテキストデータをディープラーニング(深層学習)技術を用いて構築されたニューラルネットワークによる事前学習済みの言語モデルです。
日本語を含むデータで構築された大規模言語モデルも多く公開されています。
基盤となるモデルを切り替えながら、BERTやRoBERTa、DeBERTa、GPT系などの手法で構築されたモデルが記事の分類精度にどのような影響を与えるかを確認。
また、モデルのパラメータ数の違いによる影響も検証し、実利用に当たり最適な構成を検討します。
システム構成
<学習データの作成>
トピック(タイムラインページ)の管理ツールから現在登録されている記事のIDをトピック別に取得し、記事IDの情報をもとに社内のコンテンツ管理サーバーから実際の記事本文を抽出します。
抽出した記事にはタイムラインページの名前をラベル(クラス)として付与し、多クラス分類のタスクとして扱います。同一の記事が複数のタイムラインページで使用されることもありますが、これは稀なケースであるため、今回はマルチラベルではなくシングルラベルの問題として取り扱っています。また、ラベルが全く付与されていない記事も存在するため、いくつかの条件に基づきラベルなしのデータセットも同時に作成しています。
<機械学習>
完成したデータセットをIDCFのGPUクラウド上に移し、記事とラベルの関係を学習します。
現在は推論環境もGPUクラウド上に構築していますが、コストパフォーマンスを考え、推論はCPUサーバー上で動かすことを検討しています。
GPUクラウドの利用に当たっては、既存システム(アプリケーションサーバーなど)でIDCFの環境を導入していたこともあり、環境構築をスムーズに行うことができました。
使用言語:Python
深層学習フレームワーク:PyTorch
ライブラリ:Transformers, PyTorch Lightning
進捗状況と計画
現在、ローカル環境で開発した機械学習のコードをGPUクラウドに移行し、基盤モデルに対しファインチューニングを行っています。
学習データの一部は評価データとして活用し、記事の分類性能をモデルごとに確認しているところです。
今回のプロジェクトは将来的な実利用を念頭に開発を進めています。
公開されている大規模言語モデルには開発元が定める利用規約が存在します。
商用不可のものや利用が制限されている場合もあり、細かく内容をチェックし、実際に利用が可能なものを選定します。
海外の新聞社では記事のバックナンバーを管理している資料室のことをモルグ(morgue)と呼んでいます。
モルグとは遺体安置所のことで、古くなって死んでしまったネタ(記事)が保管されていることに由来しています。
時事通信にもたくさんの過去記事が眠っています。
ディープラーニングや言語モデルのような新しい技術を利用することで、彼らを目覚めさせ、これまでに蓄積した知識から新しいサービスなどに繋げたいと考えています。
また、社内業務の効率化のために、AIを活用して記事の自動校正や類似記事の検索などに取り組んでいきたいと考えています。
2024年11月時点
発生した課題や苦労した点をどのように克服しましたか?
ラベル付き記事の分類以上に難しかったのは、ラベルが付与されていない記事の扱いでした。すべての記事がトピック(タイムラインページ)に格納されるわけではなく、多くの記事はトピックにひも付かないまま掲載されています。このため、ラベル付き記事のみでファインチューニングしたモデルでラベル付けを行うと、本来ラベルが不要な記事にも何らかのラベルが推薦されてしまう問題が生じました。
そこで、トピックに分類されていない記事の傾向を分析しました。具体的には、記事の重要度や本数を調査し、どのトピックにも分類されなかった記事を特定の条件でフィルタリング、その中から記事をランダムにピックアップして「該当なし」というラベルを付与しました。また、学習データ全体における「該当なし」の割合を適切に調整することで、モデルの精度向上を図りました。
上手くいった点について教えてください
今回は、日本語で構築された事前学習済みの言語モデルを使用しました。事前学習の構築方法やトークナイザー(文字列をトークンに変換する仕組み)の違いを考慮し、複数のモデルに対してファインチューニングを行い、分類精度を比較しました。
実験では、Hugging Face上で公開されている5つのモデルを比較しました。
- tohoku-nlp/bert-base-japanese-whole-word-masking
- tohoku-nlp/bert-base-japanese-v3
- nlp-waseda/roberta-base-japanese
- ku-nlp/deberta-v3-base-japanese
- studio-ousia/luke-japanese-base-lite
さらに、より大規模な言語モデルに対しても、LoRA(Low-Rank Adaptation of Large Language Models)を用いたファインチューニングを試みました。しかし、GPUのCUDA Capabilityの違いによりライブラリが動作しないケースが発生したため、今回は実施を見送りました。
実験の結果、「tohoku-nlp/bert-base-japanese-v3」が今回のタスクに最適であることが分かりました。比較作業ではバッチサイズや学習率を調整しながら分類精度を確認し、ファインチューニングに必要な時間も詳細に記録しました。この取り組みにより、実用性の高いモデルの構築を行うことができました。
各種実験は、GPU.7XLP100上に構築したJupyter Labで実施しました。サーバの初期設定及び環境構築に際しては、IDCFのテックブログを参考にしました。
プロジェクトの成果や達成した目標について説明してください
モデルの構築後、推論環境の整備を進めました。推論とは、モデルに新たなデータを入力し、その出力結果を得るプロセスを指します。実行環境に関するテストを実施した結果、推論に関してはGPUを使用せず、IDCFクラウド上にある既存システムのCPU環境でも十分な速度でストレスなく回答を出力できることが確認できました。
現在、この推論システムは新しい記事が配信されるたびに自動で稼働し、記事がどのトピックに該当するか、あるいは該当しないかを分類しています。分類結果は社内のコミュニケーションツールを通じて関係者にチャット形式で通知されます。編集者は通知された推論結果を確認した上で、編集ボタンから記事の格納作業を行っています。

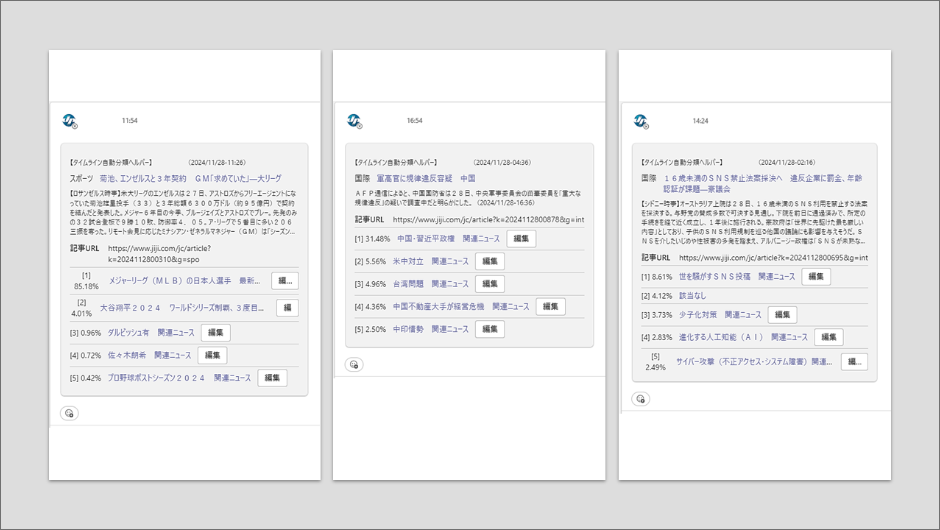
今後の計画や展望について教えてください
プロジェクトの終盤では、記事分類以外のタスクにも挑戦しました。その一つが見出しの生成です。これは過去の記事データを用いて見出しと本文の関係を機械学習し、新たな本文に対してそれに適した見出しを生成するというものです。本タスクは、文章要約の一種と言えます。
このシステムには、T5(Text-to-Text Transfer Transformer)という事前学習済みの言語モデルを使用しました。見出しと本文をペアとしてファインチューニングを行い、見出し生成に特化したモデルを構築しました。
今後は、このモデルを活用し、記事作成時の見出し付けを支援するツールの実用化を目指します。このツールは、記者が見出しを作成する際の参考情報として役立つことが期待されています。






