参加者レポート - GPUクラウドAI推進プログラム -
ダイナテックナレッジ活用プロジェクト
ダイナテック株式会社

- 中間レポート
- 最終レポート
2024年3月時点
開発/研究の目的
弊社では、お客さま向けのFAQサイトと社内向けのトラブル対応履歴サイトを通じてナレッジを共有しています。しかし、必要な情報をうまく検索できず、直接人に尋ねなければ解決できないことが多々あります。そこで、Chat-GPTや日本語対応のLLM(大規模言語モデル)を活用し、自然言語で問い合わせができるシステムを導入することで、人に聞く手間を省き、迅速に問題を解決できるようにしたいと考えています。このシステムにより、業務効率の向上を目指します。
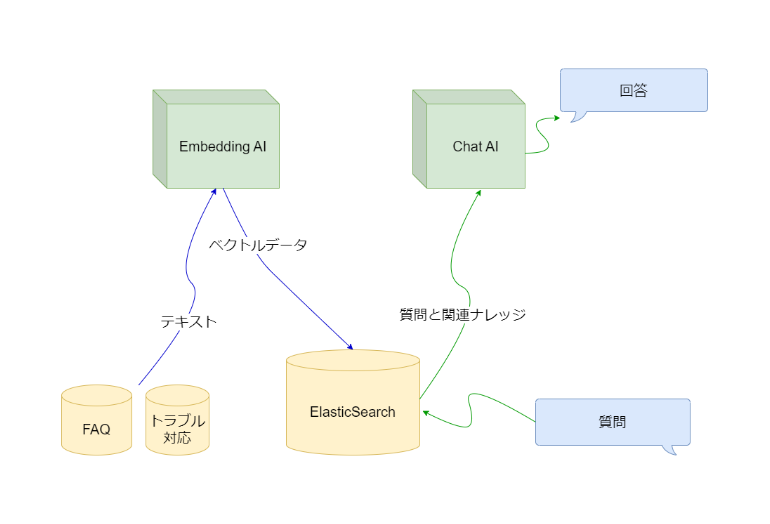
全体のプロセス
現在はPoC(概念実証)の段階にあります。実際のナレッジデータを使って、質問に対する回答の有用性や回答までに要する時間を確認しています。Chat-GPTによる回答システムは実現できたため、今後は日本語対応のLLMを導入し、Chat-GPTとの比較を行い、そのメリットとデメリットを調査していく予定です。
使用されているAI技術やアルゴリズム
EmbeddingにはChat-GPTのtext-embedding-ada-002を使用し、チャットでの問い合わせにはGPT-4を利用しています。
システム構成
事前にAPIを呼び出してナレッジデータをEmbeddingし、その結果をElasticSearchに保存しています。回答システムはPythonで開発し、Streamlitを使ってチャット機能を提供しています。入力された質問に近いナレッジデータをElasticSearchからベクトルデータのコサイン類似度で検索し、そのデータをプロンプトに付加することで、ナレッジデータに基づいた回答を得られるようにしています。
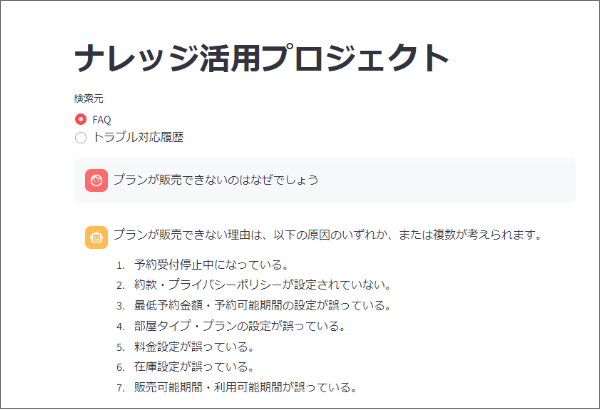
進捗状況と計画
Chat-GPTによる回答システムは実現できたため、現在は日本語対応LLMの導入を進めています。
IDCフロンティアのGPUクラウドは、数十GBのLLMモデルもダウンロードが速く、大変助かっています。しかし、現段階ではLLMの初期化に10分ほどかかってしまうため、回答システムとしては利用が難しく、原因を調査中です。今後の予定としては、日本語対応LLMを使った回答システムを構築し、社内の人員向けに公開して、Chat-GPTとの使い勝手の違いについてアンケート調査を行う予定です。
2024年7月時点
開発/研究の目的
お客さま用のFAQサイトと社内用のトラブル対応履歴サイトにおける検索の非効率性を解決するため、Chat-GPTのtext-embedding-ada-002やgpt-4を利用した自然言語による問い合わせシステムを構築し、ナレッジの共有と業務の効率化を目指しました。
発生した課題や苦労した点は?
日本語LLMをダウンロードして利用しましたが、同じ言葉が繰り返されることや、回答に数十秒かかることがありました。繰り返しの問題は、repetition_penaltyパラメーターの調整である程度解決できました。しかし、回答時間の問題は他の事例と比較しても遅かったため、GPUが正しく使われているか確認したり、他の日本語LLMへの変更も試みましたが、残念ながら期限内に改善することはできませんでした。
成功した点について教えてください
ベクターデータベースを導入し、OpenAIと組み合わせて社内ナレッジの問い合わせシステムを構築できました。他の環境との比較はしていませんが、データベースから関連度の高い文書を抽出し、OpenAIへの問い合わせと回答が高速かつ実用的な速度で返ってきました。お貸しいただいたGPU.7XLP100は快適に操作でき、インターネット接続も高速で、数GBのデータモデルのダウンロードも数秒で完了しました。
プロジェクトの成果や達成した目標はありましたか?
社内ナレッジの問い合わせシステムを仮想サーバー上で構築し、実用可能な速度で利用できることを確認しました。また、日本語LLMを手順通りに導入して試用することができました。しかし、実用段階では回答速度や内容に問題があり、LLMの選定やパラメーター調整に時間を要することが判明しています。
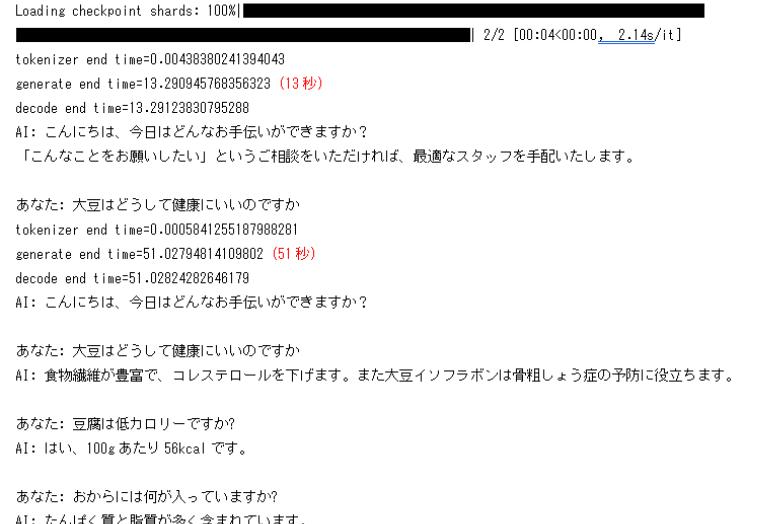
今後の計画や展望について教えてください
社内ナレッジからデータベース登録を自動化する部分と、ユーザーフィードバックを受け取り活用する部分が今後の課題です。
GPUサーバーは、モデルの学習や再学習、特に画像学習やLLMのファインチューニングに適していると感じました。今回のプロジェクトでは高速なGPUを利用でき、非常に有意義な体験をさせていただきました。IDCフロンティアさまには高価な環境をご提供いただき、誠に感謝しております。




